
How to Train a Finance Deep Research Agent: Design Principles and Lessons Learned
We built a finance deep research agent from scratch and trained it using reinforcement learning (RL). Rather than a step-by-step tutorial, this post focuses on the design philosophy, key decisions, and lessons learned in building the system. Code and training configurations are open-sourced in AgentscopeTuner.
1 Introduction
1.1 Defining Financial Deep Research
Imagine you are a financial analyst asked: “Analyze overcapacity in the photovoltaic industry over the past two years and assess its impact on leading companies’ profitability.”
The challenge lies not in writing a report, but in conducting research. Real-world investment analysis rarely starts with drafting. Analysts first form preliminary judgments, clarify the research agenda, and define verification paths: which macro indicators to track, which company filings to compare, what industry reports to consult, and which assumptions may be invalidated by new evidence.
Only then does the iterative process begin: retrieving data, reading financial statements, cross-referencing reports, and refining hypotheses as new information arrives. A Financial Deep Research Agent aims to automate this—not by generating plausible-looking text, but by producing logically sound, evidence-backed analysis through multi-round planning, retrieval, validation, and revision in a real environment.
In short, financial deep research is not a one-off generation task—it is an ongoing investigative process in an open information environment.
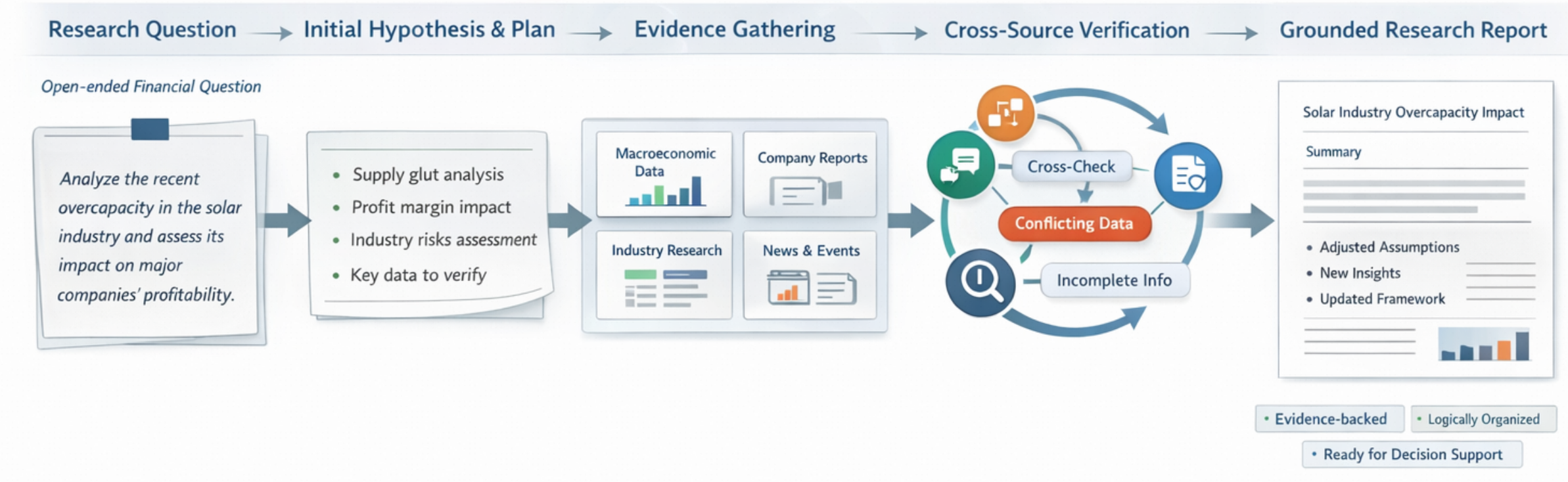
1.2 Core Challenge: Tensions Among Multi-Dimensional Objectives
Building such an agent requires balancing three interdependent—and often conflicting—objectives:
- Evidence Traceability: Financial contexts tolerate no hallucination. Every key claim must link to a verifiable source.
- Analytical Sufficiency: Research must go beyond fact retrieval to identify contradictions, build explanatory frameworks, and deliver value-added insights.
- Readability & Usability: Output must be information-dense and well-structured to directly inform business decisions.
These objectives do not scale together—they form a tension triangle. Overemphasizing factuality yields cautious but shallow “data couriers.” Prioritizing analytical depth risks “compelling hallucinations”—plausible but unsupported conclusions. Focusing on polished output may suppress necessary exploration, yielding formally coherent but substantively conservative reports. The core challenge is finding a stable equilibrium among these demands.
1.3 Limitations of Existing Paradigms
Mainstream approaches hit limits on open-ended, multi-objective tasks:
Workflow systems rely on rigid pipelines. Predefined agent orchestrations work for bounded tasks but fail to adapt to dynamic research questions. Analyzing “gross margin trends” versus “geopolitical supply chain risks” requires different tools, validation logic, and frameworks—static workflows cannot accommodate this variability.
Supervised Fine-Tuning (SFT) mimics writing style but does not teach research reasoning. Models learn professional phrasing and structure but cannot infer how to decompose problems, resolve conflicting evidence, or iteratively revise judgments. SFT outputs often appear credible but lack analytical progression or self-validation.
1.4 Our Approach
Once we recognized that SFT only sets a performance floor—and cannot teach research strategies—RL became the natural choice.
Our shift was from implicit imitation to explicit optimization: we defined high-quality financial research and let the model explore optimal strategies in a real tool environment.
Making this work required overcoming three barriers:
- Benchmarking: Traditional financial NLP benchmarks focus on single-turn, closed tasks and cannot evaluate multi-turn tool use or long-form reasoning. We built a formal benchmark from scratch as our North Star metric.
- Training Data: Expert-written reports with full reasoning chains are costly and cap model performance at human levels. We shifted from requiring “ground-truth answers” to only “high-quality questions.”
- Training Infrastructure: Real financial environments are noisy. We needed a reward system resistant to gaming and infrastructure engineered for high-concurrency, multi-turn RL—specifically, a caching and fault-tolerant architecture.
This post details our end-to-end training process, sharing insights from benchmark design, reward engineering, and infrastructure development.

2 Defining Evaluation Criteria for Financial Deep Research
In deep research, the benchmark shapes the system’s trajectory. If evaluation misses the essence of research, optimization may improve phrasing without advancing capability. Before training, we asked: What tasks reflect real financial research? What defines a robust output? What do existing benchmarks omit?
2.1 Limitations of Existing Benchmarks
Current benchmarks (e.g., FinBen[1]) target single-turn, short-text, closed tasks—suitable for knowledge extraction but not research execution. A Deep Research Agent must:
- Plan tool calls around unknown problems;
- Organize evidence coherently across long contexts;
- Perform open-ended analysis beyond binary correctness.
Thus, we built a new benchmark aligned with real research tasks.
2.2 Benchmark Overview
Our benchmark covers five domains: macro analysis, industry research, event interpretation, stock analysis, and company research. Each includes 6 representative queries (30 total), designed by experienced analysts and paired with reference frameworks.
We limited scale because: (1) query design requires expert effort; (2) evaluating one sample often involves real tool calls and multi-dimensional judging.
Two design principles guided us:
- Domain-wise breakdown provides more diagnostic value than aggregate scores (e.g., a model may excel at macro narratives but fail on financial alignment).
- Query quality matters more than quantity—we prioritized representativeness and discriminative power to cover key research capabilities.
2.3 Evaluation Focus: Analytical Sufficiency
Strong research requires factual accuracy, analytical depth, and clear presentation. We prioritize analytical sufficiency: Did the model organize evidence and reason from it, rather than state conclusions without support?
We use pairwise evaluation: judges compare model outputs against expert references. This is more stable than absolute scoring and treats references as baselines—not rigid templates—allowing valid alternative approaches.
2.4 Evaluation Metrics ≠ Training Rewards
Evaluation metrics are not always suitable as RL rewards.
Optimizing only for analytical sufficiency—without enforcing data authenticity or citation reliability—encourages shortcuts: skipping tool calls and fabricating data.
The benchmark assesses whether a report looks like good research; training must ensure it was produced through valid methods. Hence, we designed a separate, more comprehensive reward system.
3 Training Strategy Design
Chapter 2 defined “better research.” RL introduces a new problem: evaluation metrics do not always yield effective training signals. Poor rewards teach scoring tricks, not research skills.
This chapter addresses how to convert research quality into an optimizable—and cheat-resistant—training objective.
3.1 Training Data: From Answers to Questions
Unlike SFT, RL relies on high-quality queries and well-designed rewards—not (question, answer) pairs. We focused on query design.
The training set matches the benchmark’s domain distribution and is disjoint from the evaluation set. Queries vary in difficulty, cover diverse angles and tool combinations, and yield verifiable conclusions.
We developed a finance-specific query synthesis strategy:
- Select a research direction from a taxonomy of financial question types;
- Brainstorm while gathering real data via financial tools;
- Generate a challenging question and rephrase it for diversity.
This produced ~1,000 high-quality training queries.
3.2 Reward Design: Multi-Dimensional Signals
Initially, we used the benchmark’s “analytical sufficiency” score as reward. This conflated appearing thorough with being thorough, leading to two failure modes: (1) analysis built on unreliable data; (2) formal structure without analytical depth.
3.2.1 Core Objective and Constraints
We decomposed reward into 1 core objective + 3 constraints:
- Core: Analytical Sufficiency (
rm_reward) — encourages evidence organization and insight. - Constraints: Factuality (
audit_reward), Citation Traceability (grounding_reward), Presentation Quality (presentation_reward).
This ensures deeper analysis without sacrificing grounding or usability.
Formally:

Analytical sufficiency receives highest weight—it represents the primary capability gap. Other terms act as constraints to block easy-scoring behaviors.
3.2.2 Reward Calculation: Rule-Based Scoring
End-to-end LLM scoring introduces noise that destabilizes RL (especially GRPO). Instead, we split scoring into two stages:
- Extraction: A Judge LLM extracts claims, sources, and evidence relationships.
- Rule-based scoring: Deterministic logic computes dimension scores.
Example: For “Gross margin fell from 18% to 12% per the 2024 annual report,” the LLM extracts:
- Is data explicit?
- Is a source cited?
- Do data and conclusion align?
Rules then compute audit and grounding scores. This improves stability and debuggability—score anomalies can be traced to extraction or rule logic.
3.2.3 Positive Rewards and Negative Penalties
We added simple penalties to block invalid strategies.
For example, if a rollout makes almost no tool calls, it cannot gather new information or build a reasoning chain. Such behavior receives a negative penalty.
These rules accelerate early training by pruning unproductive exploration and focusing learning on meaningful behaviors.
3.3 Predefined Workflow Scaffolding
Even with good rewards, free exploration in complex environments is inefficient.
Common failures stem not from inability to call tools, but from incoherent research flow: jumping to analysis after one data point, yielding fragmented reports. Effective research follows: problem decomposition → targeted evidence gathering → synthesis.
Early in training, we scaffolded this as Plan → Execute: the model first outlines an analysis framework, then engages in tool interaction and writing. This establishes a stable pattern without locking the path. Later, the model learns to refine the scaffold into its own strategy.
4 Building Infrastructure for Training
In inference, tools retrieve information. In RL, the tool system is the environment—the model interacts with a world that directly shapes rewards and gradients. Minor issues tolerable in inference (timeouts, API jitter, unstable responses) are amplified under parallel rollouts.
Thus, training infrastructure must not just integrate tools—it must constrain the environment to be callable, traceable, and reproducible.
4.1 From “Usable Tools” to “Trainable Environments”
Models need structured, high-signal financial data—not scattered web snippets. Financial statements, quotes, announcements, and macro indicators should be provided in computable, citable formats.
We unified our stack into Finance-MCP (open-sourced), exposing data retrieval, scraping, and search via a single MCP interface. This simplifies agent integration and enables environment control during training.
We also pre-crawled content from Tonghuashun. Much critical information lives in semi-structured pages (company profiles, industry dashboards)—not standardized tables. Real-time access is costly and unstable. Pre-crawling preserves context and stabilizes the environment, reducing reward variance from external changes.
MCP standardizes diverse data sources under one interface while logging all calls. This enables backtracking from report claims to original tool responses—essential for fact-checking and reward computation.
4.2 Three Training Environment Challenges—and Solutions
Real-world training faces three issues: cost, determinism, and robustness.
-
Cost: GRPO generates multiple trajectories per query, often repeating identical tool calls. Hitting external services repeatedly is unsustainable. → Solution: Decouple tool execution into an
**EnvService**layer with MongoDB caching. Identical(tool, args)execute once; results are reused. This cuts cost and isolates external volatility. -
Determinism: Non-deterministic tool responses make reward changes uninterpretable. → Solution: Caching ensures identical inputs yield identical outputs, improving reproducibility.
-
Robustness: APIs suffer timeouts, rate limits, malformed responses, and parsing errors. Even Judge LLMs can jitter. → Principle: Single-point failures must not crash training. → Implementation:
-
- Tool calls: retry and return errors;
- Parsing: apply fault-tolerant recovery;
- Scoring: on grader failure, return
score=0and log (don’t crash batch); - Judge LLM: use retries and fallbacks.
This trades minor scoring inaccuracies for training continuity. Infrastructure like this doesn’t raise model ceilings—but it determines whether training runs at all. For RL, these are prerequisites, not details.
5 Experimental Results
We evaluated policy changes via training curves and external benchmarks.
Final reward combines:
rm: analytical sufficiencyaudit: factualitygrounding: citation traceabilitypresentation: output quality
(Each dimension: 0–1)
5.1 Training Dynamics: Gains from Analytical Capability
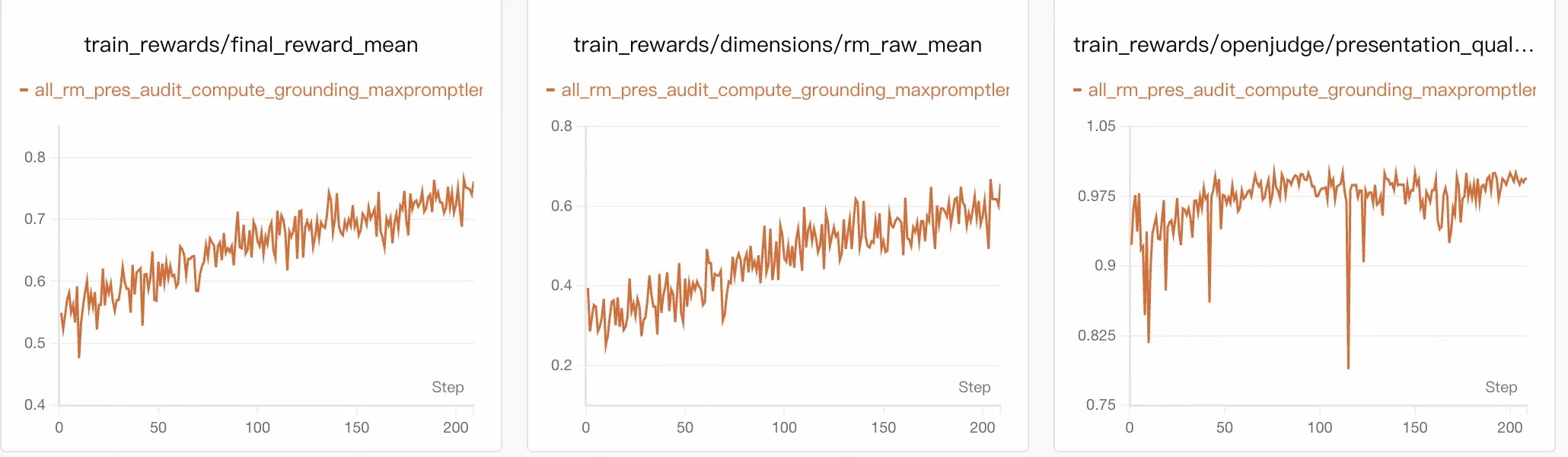
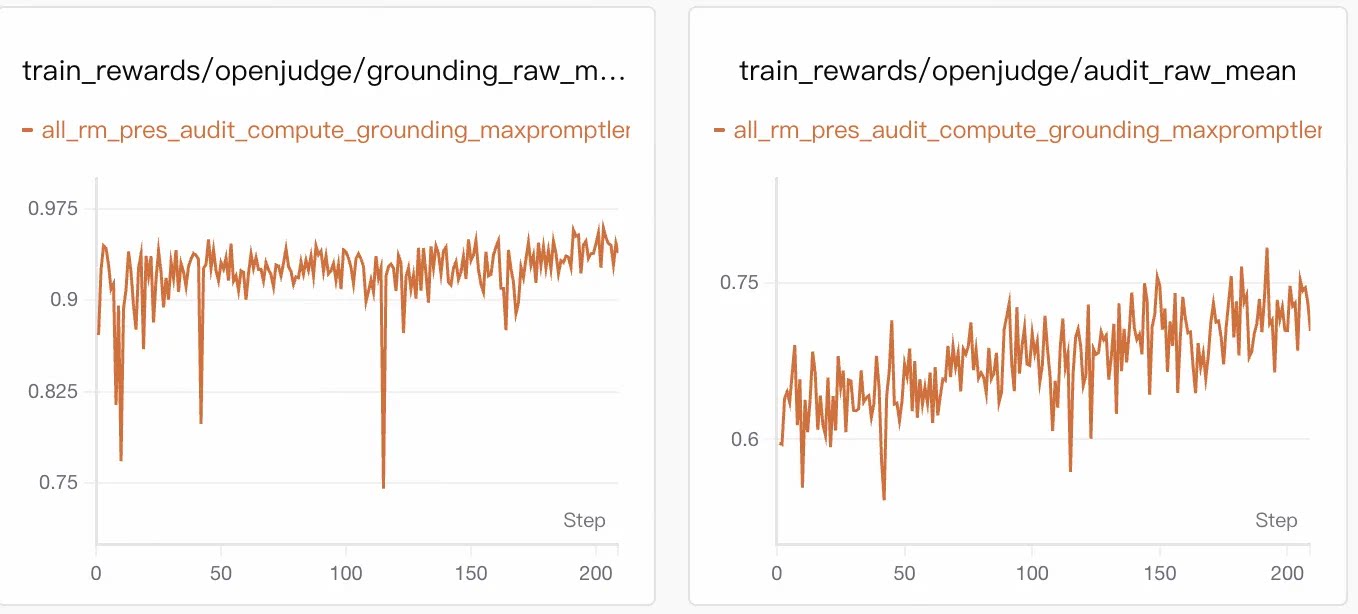
final_reward_mean rose steadily from ~0.54 to ~0.75. The largest gain came from rm_raw_mean, which increased from ~0.30 to >0.60—confirming RL primarily improved analytical sufficiency.
Constraint metrics remained stable:
presentation> 0.95grounding≈ 0.90–0.95auditrose slowly from ~0.60 to ~0.73
Gains came from deeper analysis—not from relaxing constraints.
5.2 External Evaluation: Gains Beyond Finance
On DeepResearch Bench[2], our method scored 0.476, outperforming:
base30b(0.127)tongyidr(0.277)claude3.7(0.422)
| Model | Finance | Others | Overall |
|---|---|---|---|
| Qwen3-30B-A3B-Instruct | 0.184 | 0.118 | 0.127 |
| Tongyi DeepResearch | 0.296 | 0.274 | 0.277 |
| Claude 3.7 | 0.417 | 0.423 | 0.422 |
| Ours | 0.479 | 0.475 | 0.476 |
Improvements span both finance and non-finance subsets and appear consistently across comprehensiveness, insight, instruction following, and readability. This suggests RL reinforced a transferable research process, not just financial style adaptation.
5.3 Case Study
Task: “In-depth research on Chinese enterprises achieving product-led internationalization through brand expansion.”
| Dimension | Pre-RL | Post-RL |
|---|---|---|
| Entity Selection | Changying, Xingyu, Moutai — weak alignment | Anker, Zeeho, Loctek — strong alignment |
| Evidence & Citations | ~10 citations, sparse coverage | ~21 citations, covering finance, channels, localization |
| Analytical Structure | Parallel summaries, no central thread | Typology by export path, then structured analysis |
| Conclusion Quality | Descriptive summary | Abstracted pattern: “OEM → brand-led globalization” |
RL improved research behavior—not just writing style—across entity selection, evidence gathering, structuring, and synthesis.
6 Pitfalls and Reflections: Engineering Realities of RL Training
The biggest challenges were not algorithmic—they were environmental. Success in multi-turn tool-use RL depends on:
- Environmental stability
- Room for meaningful exploration
- Reliable evaluation signals
6.1 Environmental Instability Encourages Shortcuts
Real financial APIs suffer rate limits, timeouts, and jitter. Early experiments showed models avoiding tool calls and fabricating data when exposed to instability.
Caching, state freezing, and error isolation are not just optimizations—they are core to training design. They reduce noise that misleads policy learning.
6.2 Capability Improvements Are Asynchronous
Under multi-dimensional rewards, capabilities improve at different rates. Easily optimized dimensions (e.g., presentation) advance first; integrated reasoning (e.g., analysis) lags.
In our case, analytical sufficiency drove gains, while factuality and grounding stabilized gradually. Temporary dips in individual metrics are normal. Avoid frequent reward-weight tuning—verify direction first, then allow convergence.
6.3 Evaluation Stability > Complexity
In RL (especially GRPO), reward variance corrupts advantage estimation. Noisy evaluation derails policy updates.
We separated understanding (LLM-based extraction) from scoring (rule-based calculation). This is less flexible but more stable and debuggable. For RL, a stable evaluator often matters more than advanced training tricks.
Key Requirements for Minimal Reproduction
To replicate this paradigm, these components are essential:
| Core Module | Minimum Requirement |
|---|---|
| Foundation Model | Basic multi-turn tool-use capability, or SFT-aligned baseline |
| Data Engine | Small, diverse seed queries; no ground-truth answers needed |
| Tool Execution | Unified structured interface with call-chain tracing |
| Reward Design | Analytical sufficiency as core; factuality, grounding, presentation as constraints |
| Evaluation Infra | Pipeline combining semantic extraction and rule-based scoring |
| Training Infra | Noise isolation, call caching, and safe degradation for edge cases |
Key takeaway: For financial deep research, the hardest part of RL is not “how to update the model,” but “how to present a learnable environment.”
One-Sentence Summary
Training a Financial Deep Research Agent is not about generating polished reports—it is about defining good research and translating it into evaluable, feedback-rich, optimizable signals. Only with a clear and stable mechanism can the model learn effective research strategies.
References
- Finance-MCP: https://github.com/flowllm-ai/finance-mcp
- Financial Workflow Examples: https://github.com/cuiyuebing/agentscope-samples/blob/dev_open_alias_all/alias/docs/financial_analysis.md
- Agentscope: https://github.com/agentscope-ai/agentscope
- Agentscope-Samples: https://github.com/agentscope-ai/agentscope-samples
- AgentJet: https://github.com/modelscope/AgentJet
- Xie, Q., et al. (2024). FinBen: A Holistic Financial Benchmark for Large Language Models. arXiv:2402.12659.
- Du, M., et al. (2025). DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents. arXiv:2506.11763.
- FInance Tool API:https://basic.10jqka.com.cn/